
|
기계 학습과 데이터 마이닝 |
|---|
 |
은닉 마르코프 모형(영어: hidden Markov model, HMM)은 통계적 마르코프 모형의 하나로, 시스템이 은닉된 상태와 관찰가능한 결과의 두 가지 요소로 이루어졌다고 보는 모델이다. 관찰 가능한 결과를 야기하는 직접적인 원인은 관측될 수 없는 은닉 상태들이고, 오직 그 상태들이 마르코프 과정을 통해 도출된 결과들만이 관찰될 수 있기 때문에 '은닉'이라는 단어가 붙게 되었다. 은닉 마르코프 모형은 동적 베이지안 네트워크로 간단히 나타낼 수 있으며, 은닉 마르코프 모형의 해를 찾기 위해 전향-후향 알고리즘을 제안한 스트라토노빅의 최적 비선형 필터링 문제와 밀접한 관련이 있다. 한편 은닉 마르코프 모형에 사용된 수학적 개념들은 바움(L. E. Baum)과 그의 동료들에 의해 정립되었다.
마르코프 연쇄와 같은 단순한 마르코프 모형에서는 상태를 관찰자가 직접적으로 볼 수 있으며, 그러므로 상태가 전이될 확률은 단순히 모수(parameter)들로 표현될 수 있다. 반면 은닉 마르코프 모형에서는 상태를 직접적으로 볼 수 없고 상태들로부터 야기된 결과들만을 관찰할 수 있다. 각각의 상태는 특정 확률 분포에 따라 여러 가지 결과를 도출해 낼 수 있으므로, 은닉 마르코프 모형로부터 생성된 결과들의 나열은 기저에 은닉된 상태들에 대한 정보들을 제공하고 있다고 생각할 수 있다. 여기서 단어 은닉(Hidden)이 모델의 모수를 가리키는 것이 아니라 모델이 거쳐가는 연속된 상태를 지칭하는 것에 주의해야한다. 은닉 마르코프 모형에서 모수들이 정확히 알려졌음에도 불구하고 여전히 ‘은닉’ 마르코프 모형로 불리는 이유는 결과를 야기하는 상태들이 근본적으로 은닉되어있어 관찰할 수 없기 때문이다.
은닉 마르코프 모형은 시간의 흐름에 따라 변화하는 시스템의 패턴을 인식하는 작업에 유용하다. 예를 들어 음성 인식, 필기 인식(en:Handwriting recognition), 동작 인식(en:Gesture Recognition), 품사 태깅(en:Part-of-speech tagging), 악보에서 연주되는 부분을 찾는 작업, 부분 방전(en:Partial discharge),생물정보학 분야에서 이용된다.
은닉 마르코프 모형은 은닉 변수가 독립되지 않고 마르코프 과정을 통해 변화하면서, 각 과정에서 혼합 요소를 선택하는 혼합 모델의 일반화로 볼 수 있다. 최근 이러한 은닉 마르코프 모형은 더 복잡한 자료 구조들과 안정적이지 않은 데이터들을 모델링할 수 있도록 이중 마르코프 모형, 삼중 마르코프 모형 등으로 일반화되고 있다.
역사
마르코프 연쇄
은닉 마르코프 모형의 창시자는 러시아의 수학자 안드레이 마르코프(Andrey Andreyevich Markov; 1856-1922)다. 마르코프는 1906년 마르코프 '연쇄'라는 단어를 처음 언급한 이론을 발표. 하였으며, 1913년에는 이를 이용하여 러시아 문자들의 순서에 대한 연구를 진행하였다.
1931년에 이르러 러시아 수학자 안드레이 콜모고로프(Andrey Kolmogorov)가 마르코프 연쇄의 상태 공간을 가산 무한 집합으로 확장시켜 이 이론을 일반화하였다. 마르코프 연쇄는 20세기 초반 물리학계의 중요한 연구 주제였던 브라운 운동과 에르고딕 가설과 연관성이 있는 것으로 밝혀져 많은 관심을 받았으나, 정작 마르코프 자신은 해당 마르코프 연쇄를 큰 수의 법칙을 서로 의존적인 사건들로 확장시키는 수학적 일반화의 관점을 선호하였다. 확률 및 통계학에서 마르코프 연쇄는 주로 이산 상태 공간을 가지며 마르코프 특성을 따르는 확률 과정을 의미한다.
은닉 마르코프 모형으로의 발전
1940년대 계산 과학의 급격한 발전과 더불어 비선형적이고 확률적인 시스템들의 해를 찾기 위한 알고리즘을 개발하기 위해 많은 과학자들이 이 분야에 뛰어들었다. 전향-후향 재귀법(forward-backward recursion)과 주변 다듬질 확률(marginal smoothing probability)등에 대한 이론이 스트라토노빅(Ruslan L. Stratonovich)에 의해 1950년대 후반 최초로 논의되었고, 1960년대 후반 바움(Leonard E. Baum)에 의해 은닉 마르코프 모형의 모수들을 찾아내는 바움-웰치 알고리즘이 발표되면서 은닉 마르코프 모형에 대한 연구가 활발히 진행되기 시작하였다. 1967년 앤드루 비터비(Andrew Viterbi)는 동적 프로그래밍을 이용하여 관찰된 사건들이 도출될 확률이 가장 높은 은닉 상태들의 순서를 찾아내는 비터비 알고리즘을 발표하였다.
은닉 마르코프 모형의 응용
은닉 마르코프 모형은 1970년대 음성 인식 분야에서 응용되기 시작하였으며, 1980년대 후반에는 DNA의 서열을 분석하는 데 사용되기 시작하였다. 현대에는 음성 인식, 계산언어학, 생물정보학등에 사용되고 있다.
항아리를 이용한 설명
은닉 마르코프 모형의 이산적인(Discrete) 관점에서 은닉 마르코프 모형은 복원 추출을 하는 항아리 문제를 일반화 시킨 것이라고 볼 수 있다. 다음과 같은 예제를 생각해 보자. 관측자에게 보이지 않는 방이 있고, 그 안에 요정이 있다. 방에는 항아리 가 존재한다. 각각의 항아리에는 으로 이름이 붙은 공들이 섞여서 들어가 있고, 항아리의 공들이 섞인 상태는 알려져있다. 요정은 방 안의 항아리를 하나 고르고, 항아리 안에서 무작위로 공을 하나 꺼내어 컨베이어 벨트에 올려둔다. 관측자는 컨베이어 벨트 위의 공의 순서를 관측할 수는 있지만, 해당 공들이 뽑혔던 항아리의 순서는 알 수 없다. 요정이 공을 뽑을 항아리를 고를 때는 다음과 같은 특별한 규칙을 따른다 : 번째 공을 뽑기 위한 항아리는 무작위 숫자와 번째 공을 뽑기 위해 선택한 항아리에만 영향을 받는다. 현재 항아리로부터 하나보다 더 전에 선택된 항아리는 현재 항아리의 선택에 직접적으로 영향을 주지 않는다. 이러한 규칙은 주로 마르코프 특성 (Markov Property)이라 불리며, 따라서 이것은 마르코프 과정 (Markov Process) 이라고 불린다. 이에 대한 설명은 그림 1의 위쪽에 잘 나타나있다.




마르코프 과정 자체는 관측될 수 없고 오직 컨베이어 벨트 위의 공의 나열만 관측이 가능하기 때문에 "은닉 마르코프 과정"이라고 불린다. 이는 그림 1의 아래 부분에 잘 나타나있다. 그림에서 묘사된 바와 같이, 관찰자는 각 상태에서 뽑혀 나온 만을 관측할 수 있다. 심지어 관찰자가 항아리들의 내부의 공들의 비율을 알고 있고 의 세 공들을 관측했더라도 관측자는 여전히 요정이 세 번째 공을 뽑은 항아리(= 상태)를 알 수는 없다. 다만 관측자는 세 번째 공()이 각 항아리에서 뽑혔을 가능도(likelihood)와 같은 정보들에 대해서는 계산을 할 수 있을 뿐이다.



은닉 마르코프 모형의 구조
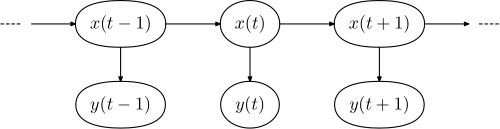
위의 다이어그램은 은닉 마르코프 모형의 일반적인 구조를 보여주고 있다. 각 원은 확률변수를 나타낸다. 확률변수 는 시간 에서의 은닉 상태(hidden state)이다. 확률변수 는 시간 에서의 관측값(observation)이다. 각 상태를 연결하는 화살표는 조건부 의존성(conditional dependency)을 나타낸다.



은닉 변수
모든 시간에 대하여 은닉 변수(hidden variable) 의 값이 주어질 때, 특정 시간 에서의 은닉 변수 의 조건부 확률 분포는 오직 은닉 변수 에만 의존하는 것을 관찰할 수 있다. 그 이전의 시간들 ()은 에 영향을 주지 않는데, 이를 마르코프 특성이라 한다. 이와 비슷하게 시간 에서 관측된 변수 의 값은 오직 은닉 변수 에만 영향을 받는다.


은닉 변수의 상태 공간
은닉 마르코프 모형의 표준적인 형태에서 은닉 변수의 상태 공간(state space)은 이산적이다. 반면 관측값들은 이산적일 수도 있고, 연속적 일 수도 있다. 이산적인 경우는 주로 범주 분포를 따르고, 연속적인 경우는 주로 정규 분포를 따른다. 은닉 마르코프 모형의 모수(parameter)로는 전이 확률(transition probability)과 출력 확률(emission probability)의 두 종류가 있다. 전이 확률은 시간 에서의 은닉 상태가 주어졌을 때 시간 에서의 은닉 상태가 선택되는데 영향을 주며, 출력 확률은 주어진 상태 에서 특정한 결과값 이 관측될 확률 분포를 나타낸다.

전이 확률
은닉 상태 공간은 범주 분포로 모델링 될 수 있는 개의 가능한 상태들 중 하나로 구성되어 있다고 가정된다. 각각의 시간 에서 은닉 변수는 총개의 가능한 상태들을 가질 수 있고, 시간 에는 은닉 변수가 개의 가능한 상태로 전이할 확률이 존재한다. 따라서 이러한 확률은 개의 전이 확률로써 표현될 수 있다. 이 때 한 상태의 전이 확률의 합은 항상 1이 되어야 한다. 따라서 전이 확률 행렬은 마르코프 행렬이다. 다른 전이 확률들을 모두 알고 있을 때 마지막 전이 확률은 당연하게 도출될 수 있기 때문에 전체 전이 모수(transition parameter)의 수는 이다.





출력 확률
각 개의 가능한 상태들에 대하여 특정 시간에서의 은닉 변수들이 주어졌을 때 관측 변수들의 분포를 제어하는 출력 확률들의 집합이 존재한다. 이 집합의 크기는 관측 변수들의 특성에 의해 결정된다. 예를 들어, 만약 관측 변수가 범주 분포의 영향을 받고 개의 가능한 값을 가질 경우 개의 독립된 모수들이 존재함을 알 수 있다. 따라서 모든 은닉 상태들에 대해 전체 출력 모수들의 개수는 개가 된다. 반면에 만약 관측 변수가 임의의 다변량 정규분포를 따르는 차원 벡터일 경우 평균에 영향을 주는 개의 모수와 공분산 행렬에 영향을 주는 개의 모수가 존재하므로 전체 개의 출력 모수가 존재하게 된다. 이런 경우에는 값이 작지 않다면 관측 벡터의 각 원소들을 서로 독립으로 가정하거나, 서로 독립이면서 고정된 수의 인접 원소들을 가진다는 가정 등을 통해 공분산의 특징을 제한하는 것이 훨씬 실용적이다.





출력 확률의 확률 분포
은닉 마르코프 모형은 마르코프 과정에 기반하여 상태들이 특정한 확률 분포에 따라 결과들을 출력하는 모델을 만들 수 있다. 이러한 확률 분포의 예시 중 하나로 정규 분포가 있으며, 이 경우 출력 확률이 정규 분포를 따른다고 이야기 할 수 있다. 출력된 결과값이 둘 이상의 혼합 정규 분포에 의해 표현된다면 훨씬 더 복잡한 시스템을 표현할 수도 있다. 이 경우 특정 결과가 관찰될 확률은 정규 분포들 중에서 하나를 선택할 확률과 그 정규 분포에서 해당 관측 값을 출력할 확률의 곱이 된다.
추론 문제에의 응용

5 3 2 5 3 2
4 3 2 5 3 2
3 1 2 5 3 2
가장 가능성이 높은 상태들의 나열은 각각의 경우에 대하여 해당 상태가 나열될 확률과 주어진 관찰결과가 도출될 확률의 결합 확률로 표현될 수 있다. 위의 문제는 비터비 알고리즘을 통하여 해를 찾을 수 있다.
은닉 마르코프 모형은 다양한 추론 문제들과 깊은 관련을 가지고 있다. 그러한 추론 문제들에 대한 예시들은 아래와 같다.
일련의 사건들이 관찰될 확률에 대한 추론
이 추론의 목표는 어떠한 일련의 사건들이 순서대로 관찰되었을 때, 우리가 가지고 있는 확률 모델에 기반하여 해당 사건들이 관측될 확률을 계산하는 것이다. 즉,

와 같은 순서로 총 L개의 사건들(Y)이 관측되었다고 가정해보자. 그러한 사건이 일어날 확률은

와 같이 각 사건 이 일어날 수 있는 확률들의 합이다. 여기서 각각의 관측되는 사건은 은닉 변수(Hidden state)에서 도출될 수 있는 모든 경우의 수를 고려해야 하므로, 아래와 같은 관계가 성립한다.


이러한 문제는 동적 계획법에 기반한 전향 알고리즘을 이용하여 효율적으로 계산될 수 있다.
전향 알고리즘 (Forward algorithm)


전향 알고리즘은 은닉 마르코프 모형이 개의 상태를 가질 때, 시간 에서 각 상태들의 확률 분포를 구하는 방법이다. 은닉 마르코프 모형을 상태와 시간으로 나열하면 이들은 격자 모양을 가지게 되는데, 전향 알고리즘은 시간 와 상태 에 도달할 때까지 모든 경로의 확률의 합을 계속해서 보관하며 다음 시간 을 구할 때 이 정보를 이용한다.

특정 시간 에서 특정 사건 가 관찰될 확률은 시간 까지의 각 상태에 있을 확률들을 알면 시간 의 각 상태들로부터 시간 로의 전이 확률의 합과 시간 의 상태에서 사건 를 관찰할 확률의 곱으로 표현이 가능하다. 전체 상태가 개라고 할 때 특정 시간 에서 특정 상태 에 있을 확률을 수식으로 나타내면 다음과 같다.


이때 는 상태에서 상태로의 전이 확률을 나타내며, 는 j 상태에서 관측값 을 얻을 확률이다.



예시로 주어진 은닉 마르코프 모형에서 시간 t = 4일 때 상태 3에서 관측값 4를 얻을 확률은 위 수식을 통해 다음과 같이 표현 가능하다.
![\alpha _{4}(3)=[\alpha _{3}(1)*a_{{13}}+\alpha _{3}(2)*a_{{23}}+\alpha _{3}(3)*a_{{33}}+\alpha _{3}(4)*a_{{43}}+\alpha _{3}(5)*a_{{53}}]*b_{3}(o_{4})](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c274e299ac4957af76e6454136ebd0bbb8a787b)
이를 계산하기 위한 는 들로부터 구할 수 있고 는 들로부터 구할 수 있다.



- 에서의 확률 분포인 에 대한 값은 초기 상태 분포 로부터 의 식을 통해 계산한다.



특정 은닉 변수에 대한 확률 추론
와 같이 일련의 결과들이 관측되었을 때 주어진 모델에 대한 가정하에 특정한 은닉 변수들에 대한 확률을 계산하는 문제들이다.

필터링 ( Filtering )
필터링 문제는 관찰된 결과들과 이에 대한 확률 모델의 변수들이 주어졌을 때 가장 마지막 은닉 변수의 확률 분포를 묻는다. 좀 더 자연스럽게 설명하자면, 은닉 마르코프 모형의 관점에 의하여 관찰된 사건 들이 특정 확률 과정에 의해 일련의 순서로 은닉 변수 를 거쳐가면서 도출되었다고 가정했을 때 가장 마지막에 도달한 은닉 변수에 대해 기술하는 것으로 여겨질 수 있다.

수식으로는 의 값을 구하는 것으로 표현될 수 있다.

해당 문제는 전향 알고리즘을 이용하여 효율적으로 풀 수 있다.
다듬질 ( Smoothing )
다듬질은 필터링과 유사한 개념이나, 가장 마지막 은닉 변수가 아니라 확률 과정 중간의 은닉 변수에 대해 묻는다는 점에서 차이가 있다. 즉, 다듬질은 인 에 대하여 를 구하는 과정이라고 할 수 있다. 필터링과 마찬가지로 관찰된 사건들이 특정 확률 과정에 의해 은닉 변수를 거쳐가며 도출된다는 관점에서, 특정 시간 에서 만큼 상태에서의 확률 분포를 묻는 것으로 이해할 수 있다.



해당 문제는 전향-후향 알고리즘으로 은닉 변수의 다듬질된 값을 구해낼 수 있다.
가장 가능성이 높은 설명에 대한 추론
이 문제는 필터링이나 다듬질과는 달리, 특정한 관찰 결과들의 나열이 주어졌을 때 고려할 수 있는 전체 은닉 변수들에 대한 결합 확률들의 분포를 묻는다. 보통 이러한 유형의 문제는 필터링이나 다듬질이 적용되기 힘든 다른 종류의 문제들을 은닉 마르코프 모형을 이용하여 풀 때 적용가능하다. 가장 대표적인 예로는 품사 추론이 있다. 품사 추론이란 특정한 단어들의 나열이 주어졌을 때, 해당 단어들의 품사들을 추론하는 문제이다. 이 문제에 은닉 마르코프 모형을 적용한다면 관찰된 결과는 주어진 단어들의 나열에 해당하고, 은닉 변수들은 단어들의 품사로서 생각될 수 있다. 만약 이 문제에 필터링이나 다듬질 기법을 적용한다면 오직 한 단어의 품사만을 고려하게 되지만, 앞서 언급한 방법론은 각각의 품사들을 전체적인 문맥을 고려하여 추론하게 된다.
해당 방법론은 가능한 모든 은닉 변수들의 나열중 가장 확률이 높은 것을 찾는 문제로 귀결되는데, 이는 비터비 알고리즘으로 해결될 수 있다.
통계적 유의성
통계적 유의성은 은닉 마르코프 모형에서 특정한 결과들의 나열이 관찰되었을 때, 해당 결과가 어떠한 상태 은닉 변수들의 조합으로부터 비롯되었을 확률이 어느 정도인지를 나타내는 지표가 된다.전향 알고리즘의 경우 이는 어떠한 귀무 분포에 대한 은닉 마르코프 모형의 확률을 구하는 문제로서 표현될 것이고, 비터비 알고리즘을 사용한 경우에는 가장 높은 확률을 갖는 은닉 변수 순서를 구하는 문제로 표현될 것이다. 이러한 맥락에서 통계적 유의성은 은닉 마르코프 모형이 가설과 특정 결과값에 대한 연관성을 평가하는데 사용된 경우 거짓 양성률을 나타내는 것으로 생각될 수 있다.
구체적인 예제
영희와 철수는 멀리 떨어져서 살고 있기 때문에 안부를 전화로 물을 수 밖에 없다. 철수의 일과는 크게 '걷거나', '쇼핑을 하거나', '집안을 청소'하는 세가지로 있는데, 무엇을 할지는 그 날의 날씨에 따라 결정된다. 영희는 철수가 살고 있는 지역의 날씨에 관해서 정확히는 모르고 대략적인 경향성만을 알고 있을 뿐이다. 영희는 철수와의 통화내용에 기반하여 그 지역의 날씨를 예측해보려고 한다.

영희는 날씨가 이산 마르코프 연쇄로 동작한다고 믿는다. "비"가 오거나(Rainy) "맑음(Sunny)"이라는 두 가지 상태가 있다는 것을 알지만 직접 관찰할 수 없기 때문에 정확히 알 수는 없다. 즉, 날씨는 영희에게 은닉 상태이다. 철수는 그 날의 날씨에 따라서 걷거나, 쇼핑을 하거나, 청소를 하고 영희는 전화 통화를 통해 그것들을 관찰(observations)한다. 이는 은닉 마르코프 모형의 좋은 비유가 될 수 있다.
영희는 그 지역의 일반적인 날씨의 경향성과 철수가 특정한 날씨에 주로 어떤 행동을 하는지에 대해 알고 있다. 즉, 영희의 은닉 마르코프 모형의 모수는 모두 알려져있다는 것이다. 이 파이썬 프로그래밍 언어로 다음과 같이 나타내 질 수 있다:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}
이 코드에서, start_probability는 초기 확률 분포로서 철수가 영희에게 첫 번째 전화를 했을 때 은닉 마르코프 모형이 어떤 상태에 있을 것이라는 그녀의 믿음을 의미한다. (그녀는 철수가 사는 지역이 주로 비가 온다는 사실을 알고 있다) {'Rainy': 0.57, 'Sunny': 0.43}이다. transition_probability는 마르코프 연쇄에서 행해지는 날씨의 변화를 나타낸다. 위의 예시에서 오늘 비가 오면 내일 맑을 확률은 30%이다. emission_probability는 매일 철수가 어떤 행동을 할지를 나타낸다. 만약 비가 온다면, 철수는 50%의 확률로 집을 청소할 것이고, 그렇지 않고 날씨가 맑다면 60%의 확률로 산책을 나갈 것이다.
유사한 예시는 비터비 알고리즘 페이지에서 더 자세히 확인할 수 있다.
은닉 마르코프 모형의 학습
관찰 결과의 나열이 주어졌을 때 은닉 마르코프 모형의 모수를 학습하는 과정은 해당 결과가 나올 확률을 극대화 시키는 전이 확률과 출력 확률을 구하는 것이다. 이 과정은 대체로 주어진 관찰 결과에 기반하여 최대 가능도 방법으로 유도한다. 이러한 문제를 정확히 풀 수 있는 쉬운 알고리즘은 알려지지 않았지만, 국지적 극댓값들은 바움-웰치 알고리즘이나 Baldi-Chauvin 알고리즘 등을 통해 효율적으로 계산될 수 있다. 바움-웰치 알고리즘은 기대값 최대화 알고리즘의 특별한 경우이다.
가 시간 에서 가능한 값들이 개 존재한다고 하자. 가 시간 에 대해 독립적이라고 가정한다면 전이 확률은 시간독립적 전이 확률 행렬 로 표현될 수 있다.



-
.

초기 분포()와 관찰된 결과는 각각 과 의 형태로서 주어진다.


관측된 결과변수 는 가능한 개의 값들 중 하나를 취한다. 따라서 특정한 시간 의 상태 에서 어떠한 결과가 관측될 확률은 아래와 같이 기술될 수 있다.


-
.

또한 가능한 모든 상태 와 결과 값 의 조합은 x 크기의 행렬 로 기술된다.

따라서 은닉 마르코프 모형은 와 같이 기술된다. 바움-웰치 알고리즘은 의 국지적 극댓값을 찾는데, 이는 곧 주어진 관찰 결과가 도출될 확률을 극대화하는 은닉 마르코프 모형의 모수 를 찾는 과정이라 할 수 있다.



확장
연속적 상태 공간으로의 확장
위에서 고려된 은닉 마르코프 모형에서는 은닉 변수의 상태공간은 이산이다. 반면에 관찰된 결과값은 이산적일 수도 있고 연속적일 수도 있다. 은닉 마르코프 모형은 연속적인 상태 공간들을 허용하는 것으로 확장될 수 있다. 모든 변수들이 선형적이고 가우시안 분포를 따르는 마르코프 프로세스가 선형 동적 시스템(en:Linear dynamical system)이 되는 것이 그러한 확장의 예시이다. 이와 같은 선형 동적 시스템은 간단하기 때문에 칼만 필터를 이용하여 정확한 추론이 가능한 편이다. 그러나 일반적으로 연속 은닉 변수에 대한 은닉 마르코프 모형에서의 정확한 추론은 불가능하며, 확장된 칼만 필터(en:Extended Kalman filter)나 입자 필터와 같은 근사 방법이 사용되어야 한다.
다양한 사전 분포로의 확장
은닉 마르코프 모형은 생성 모델이다. 말하자면 관찰 값과 은닉 상태 사이의 결합 분포이며, 혹은 동등하게 은닉상태(전이 확률)의 사전 분포와 관찰 값의 모델이 된 주어진 상태(결과 확률)의 조건 분포이다. 위의 알고리즘은 암묵적으로 전이 확률의 균등 사전 분포를 가정한다. 그러나 다른 종류의 사전 분포로 은닉 마르코프 모형을 생성하는 것도 가능하다. 전이 확률로서 범주 분포가 주어졌다면 범주 분포의 사전 분포인 디리클레 분포를 좋은 후보로 고려할 수 있다. 전형적으로, 어떤 상태가 다른 상태보다 본질적으로 가능성이 높은지에 대한 무시를 반영하는 대칭적인 디리클레 분포가 선택된다. 이 분포의 단일 모수(집중 모수라 불리는)는 결과 전이 행렬의 관계적인 밀도(density)나 희소성(sparseness)을 조절한다. 1의 선택은 균등 분포를 산출한다. 1보다 큰 값은 상태 쌍 사이의 전이 확률이 거의 같은 밀도 행렬을 만든다. 1보다 작은 값은 각각의 원점 상태가 주어졌을 때 작은 수의 목적 상태만이 무시할 수 없는 전이 확률을 가지고 있는 희소 행렬을 야기한다. 2단계의 사전 디리클레 분포를 사용하는 것도 가능하다. 그 분포는 하나의 디리클레 분포(상위 분포)가 다른 디리클레 분포(하위 분포)의 매개변수를 통제한다. 즉, 차례대로 전이 확률 들을 통제한다. 상위 분포는 상태들의 전체적인 분포를 각각의 상태들의 발생 가능성을 결정하는 방식으로 통제한다. 그것의 집중 모수는 상태의 밀도 혹은 희소성을 결정한다. 그러한 2단계 사전 분포는 두 집중 모수가 희소 분포를 생성하기 위해 설정된다. 그 분포는 어떤 품사가 다른 것보다 더 많이 발생하는 비지도 품사 추론의 예제를 위해 사용될 수 있다. 균등 사전 분포를 가정하는 학습 알고리즘은 일반적으로 이 작업에서는 제대로 기능하지 못한다. 비균등 사전 분포 등 과 같은 이러한 종류의 모델들의 모수들은 깁스 샘플링이나 기댓값 최대화 알고리즘의 확장 버전 등을 이용하여 학습된다.
앞서 설명했던 디리클레 사전 분포를 이용한 은닉 마르코프 모형의 확장은 디리클레 분포 대신에 디리클레 과정을 사용한다. 이러한 종류의 모델은 알려지지 않고 잠재적으로 무한한 수의 상태를 감안한다. 앞서 설명한 2단계의 디리클레 분포와 비슷하게, 2단계 디리클레 과정은 자주 사용된다. 이러한 모델은 계층적인 디리클레 과정 은닉 마르코프 모형 혹은 HDP-HMM으로 줄여서 지칭된다. 이 모델은 원래 무한 은닉 마르코프 모형(Infinite Hidden Markov Model)이라는 이름으로 서술되었으나,에서 보다 형식화가 이루어졌다.
판별 모델을 이용한 확장
다른 종류의 확장은 표준 은닉 마르코프 모형의 생성 모델 대신에 판별 모델을 사용한다. 이 종류의 모델은 결합 분포를 모델링하기 보다는, 주어진 관찰 값으로부터 은닉 상태들의 조건 분포들을 모델링한다. 이 모델의 예는 소위 최대 엔트로피 마르코프 모형(Maximum-entropy Markov model)이라고 불린다. 이 모델은 로지스틱 회귀를 사용하는 상태들의 조건 분포를 모델링한다. 이 종류 모델의 장점은 관찰 값들의 임의의 특징(예를 들면, 함수)들이 모델링 될 수 있다는 것인데, 문제의 영역 특정 지식을 모델에 즉시 주입되도록 할 수 있다는 것이다. 이 종류의 모델들은 은닉 상태와 그와 관계된 관찰 값 사이의 직접적인 의존관계를 모델링 하는 데에 있어서 제한을 받지 않는다. 오히려 연관된 관찰 값과 근처의 관찰 값의 조합이나 주어진 은닉 상태로부터의 어떤 거리의 임의의 관찰 값의 실제에서의 근처 관찰 값의 특징은 은닉 상태의 값을 결정하는데 사용하기 위해 과정에 포함될 수 있다. 게다가, 이러한 특징에 대해 각각 서로에 대해 통계적으로 독립일 필요가 없다. 그러한 특징이 생성 모델에서 사용되었다면 그 경우가 될 것이기 때문이다. 마지막으로, 인접한 은닉 상태 쌍에 대한 임의의 특징은 간단한 전이 확률들 대신에 사용될 수 있다. 이러한 모델의 단점은 다음과 같다: (1) 은닉 상태들에 놓일 수 있는 사전 분포들의 종류는 엄격하게 제한되어있다; (2) 임의의 관찰 값을 보는 것의 확률을 예측하는 것은 불가능하다. 많은 보통의 은닉 마르코프 모형의 사용이 그러한 예측 확률을 필요로 하지 않기 때문에 두 번째 제한은 실제에서 자주 일어나지 않는다.
앞서 설명한 판별 모델의 변종은 선형-연쇄 조건부 무작위장이다. 이것은 최대 엔트로피 마르코프 모형의 방향 그래프 모델과 비슷한 모델들 보다는 비방향 그래프 모델(마르코프 임의 필드로 알려진)을 사용한다. 이 종류 모델의 장점은 소위 최대 엔트로피 마르코프 모형의 레이블 편향 문제로 고통받지 않아도 된다는 것이며, 따라서 더 정확한 예측을 할 수 있다는 것이다. 단점은 훈련이 최대 엔트로피 마르코프 모형의 것보다 느릴 수 있다는 것이다.
차례곱 은닉 마르코프 모형
또 다른 변형 형태는 차례곱 은닉 마르코프 모형(factorial hidden Markov model)로, 여기에서는 하나의 관측값이 하나가 아니라 개의 독립적인 마르코프 연쇄와 관련되는 것을 허용한다. 이것은 (각 연쇄가 개의 상태를 가진다고 가정할 때) 개의 상태를 가진 하나의 은닉 마르코프 모형과 동등하다. 길이 인 상태열에 대한 전방 비터비 알고리즘은 의 복잡도를 가지며, 따라서 이런 모델을 학습하는 것은 무척 어렵다. 정확한 해를 찾기 위하여 접합 트리 알고리즘이 사용될 수 있으나 이는 의 복잡도를 가진다. 현실적인 사용을 위해서는 변분법을 이용한 접근과 같은 근사화 방법이 사용될 수 있다. 위에서 언급된 모델들은 전부 은닉 상태들의 의존성의 거리를 늘리는 것으로 확장을 할 수 있다. 확장 방법은 주어진 상태가 있을 때 이 상태가 바로 앞의 상태 뿐 아니라 둘이나 셋 이전의 상태들의 영향을 받는 것을 허용하는 것이다. 이 경우 전이 확률은 인접한 세 상태를 포함하도록 확장된다. 이를 일반화하면 개의 인접 상태를 포함하도록 확장할 수 있다. 이 모델의 문제점은 인접 상태들이 개 있고, 전체 관측값이 개 있을 때(길이 인 마르코프 연쇄), 학습을 위한 동적 프로그래밍 알고리즘이 의 실행 시간을 가진다는 것이다.





삼중 마르코프 모형
다른 최근의 확장 형태는 삼중 마르코프 모형(triplet Markov model)이다. 이 모델에서는 몇몇 특수 데이터들을 모델링하기 위한 보조적인 과정(process)을 추가한다. 이 모델의 많은 변형 형태들이 제안되었다.
수학적 서술
보편적 서술
기본적인 비 베이지안 은닉 마르코프 모형은 다음과 같이 서술 될 수 있다:
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태와 관련 된 관찰을 위한 결과 모수i | |||||
| = | 상태 i에서 상태j로 가는 확률 | |||||
| = | 로 구성 된 N차원 벡터; 합이 1이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| = |
θ에 대해 모수화 된 관찰의 확률 분포 |
|||||
| ~ | ||||||
| ~ |










위의 모델에서 초기 상태 의 사전 분포가 정해지지 않았음을 상기해야 한다. 전형적인 학습 모델들은 모든 가능한 상태에 대해 이산적인 연속균등분포를 따른다고 가정한다 (특정한 사전 조건이 주어지지 않는다). 베이지안 설정에서, 모든 모수들은 다음과 같이 확률 변수와 관련되어있다:

| N,T | = | 위와 같음 | ||||
| = | 위와 같음 | |||||
| = | 위와 같음 | |||||
| α | = | 결과 모수들을 위한 공유 초 모수(hyper-parameter) | ||||
| β | = | 전이 모수들을 위한 공유 초 모수 | ||||
| = | α로 모수화 된 결과 모수들의 사전 확률 분포 | |||||
| ~ | ||||||
| ~ | ||||||
| ~ | ||||||
| ~ |





이 특징들은F와 H를 관찰들과 모수들의 임의 분포 각각을 표현하기 위해 사용한다. 일반적으로 H는 F의 켤레 사전 분포(conjugate prior)가 될 것이다. 가장 일반적인 F는 정규 분포과 범주 분포이다. 아래를 보라.
단순 혼합 모델과의 비교
위에서 언급한 것처럼 은닉 마르코프 모형에서의 각각의 관찰의 분포는 해당하는 상태에서 혼합 컴포넌트로의 상태를 가지고 있는 혼합 밀도이다. 은닉 마르코프 모형을 위한 위의 특징들을 해당 혼합 모델의 특징들과 같은 수식을 써서 비교하는 것은 유용하다.
비 베이지안 혼합 모델:
| N | = | 혼합 컴포넌트의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | i와 관련된 관찰 분포의 매개변수 | |||||
| = | 혼합 편중, 예를 들어 컴포넌트 i의 사전 확률 | |||||
| = | 로 구성 된 N-차원 벡터; 합은 이 되어야 한다. | |||||
| = | 관찰 t 컴포넌트 | |||||
| = | 관찰 t | |||||
| = | θ로 매개화된 관찰의 확률 분포 | |||||
| ~ | ||||||
| ~ |





베이지안 혼합 모델:
| N,T | = | 위와 같음 | ||||
| = | 위와 같음 | |||||
| = | 위와 같음 | |||||
| α | = | 컴포넌트 모수들을 위한 공유 초 모수 | ||||
| β | = | 혼합 편중들을 위한 공유 초 모수 | ||||
| = | α로 매개화 된 컴포넌트 모수의사전 확률 분포 | |||||
| ~ | ||||||
| ~ | ||||||
| ~ | ||||||
| ~ |

예시
다음의 수학적 기술들은 구현의 편의를 위해 상세히 쓰이고 설명되었다. 관찰 결과들이 정규 분포를 따르는 전형적인 비 베이지안 은닉 마르코프 모형은 다음과 같다.
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태i에서 상태j로 가는 확률 | |||||
| = | 로 구성 된N-차원 벡터; 합이 이 되어야 한다. | |||||
| = | 상태 i와 관련된 관찰들의 평균 | |||||
| = | 상태 i와 관련된 관찰들의 편차 | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| ~ | ||||||
| ~ |




관찰 결과들이 정규 분포를 따르는 따르는 일반적인 베이지안 은닉 마르코프 모형은 다음과 같다.
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태i에서 상태j로 가는 확률 | |||||
| = | 로 구성 된N-차원 벡터; 합이 이 되어야 한다. | |||||
| = | 상태 i와 관련된 관찰들의 평균 | |||||
| = | 상태 i와 관련된 관찰들의 편차 | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| β | = | 전이 행렬의 밀도를 조절하는 집중 초 모수 | ||||
| = | 각각의 상태의 평균들의 공유 초 모수 | |||||
| = | 각각의 상태의 편차들의 공유 초 모수 | |||||
| ~ | ||||||
| ~ | ||||||
| ~ | ||||||
| ~ | ||||||
| ~ |




Categorical 관찰을 따르는 전형적인 비 베이지안 은닉 마르코프 모형은 다음과 같다:
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태 i에서 상태 j로 가는 확률 | |||||
| = | 로 구성 된N-차원 벡터; 합이 이 되어야 한다. | |||||
| V | = | Categorical 관찰들의 차원, 예를 들어 단어 어휘의 크기. | ||||
| = | j 번째 아이템을 관찰하는 상태 i를 위한 확률 | |||||
| = | 로 구성 된 V-차원 벡터; 합이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| ~ | ||||||
| ~ |




Categorical 관찰을 따르는 전형적인 베이지안 은닉 마르코프 모형은 다음과 같다:
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태i에서 상태j로 가는 확률 | |||||
| = | 로 구성 된N-차원 벡터; 합이 이 되어야 한다. | |||||
| V | = | Categorical 관찰들의 차원, 예를 들어 단어 어휘의 크기. | ||||
| = | j 번째 아이템을 관찰하는 상태 i를 위한 확률 | |||||
| = | 로 구성 된 V-차원 벡터; 합이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| ~ | ||||||
| ~ |
Categorical 관찰을 따르는 전형적인 베이지안 은닉 마르코프 모형은 다음과 같다:
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태i에서 상태j로 가는 확률 | |||||
| = | 로 구성 된N-차원 벡터; 합이 이 되어야 한다. | |||||
| V | = | Categorical 관찰들의 차원, 예를 들어 단어 어휘의 크기. | ||||
| = | j 번째 아이템을 관찰하는 상태 i를 위한 확률 | |||||
| = | 로 구성 된 V-차원 벡터; 합이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| ~ | ||||||
| ~ |
Categorical 관찰을 따르는 전형적인 베이지안 은닉 마르코프 모형은 다음과 같다:
| N | = | 상태의 수 | ||||
| T | = | 관찰의 수 | ||||
| = | 상태 i에서 상태 j로 가는 확률 | |||||
| = | 로 구성 된N-차원 벡터; 합이 이 되어야 한다. | |||||
| V | = | Categorical 관찰들의 차원, 예를 들어 단어 어휘의 크기. | ||||
| = | j 번째 아이템을 관찰하는 상태 i를 위한 확률 | |||||
| = | 로 구성 된 V-차원 벡터; 합이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| α | = | 각 상태에 대한 의 공유 집중 초 모수 | ||||
| β | = | 전이 행렬의 밀도를 조절하는 집중 초 모수 | ||||
| ~ | j 번째 아이템을 관찰하는 상태 i를 위한 확률 | |||||
| = | 로 구성 된 V-차원 벡터; 합이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| α | = | 각 상태에 대한 의 공유 집중 초 모수 | ||||
| β | = | 전이 행렬의 밀도를 조절하는 집중 초 모수 | ||||
| ~ | j 번째 아이템을 관찰하는 상태 i를 위한 확률 | |||||
| = | 로 구성 된 V-차원 벡터; 합이 되어야 한다. | |||||
| = | 시간 t에서 관찰의 상태 | |||||
| = | 시간 t에서의 관찰 | |||||
| α | = | 각 상태에 대한 의 공유 집중 초 모수 | ||||
| β | = | 전이 행렬의 밀도를 조절하는 집중 초 모수 | ||||
| ~ | ||||||
| ~ | ||||||
| ~ | ||||||
| ~ |




위의 베이지안 특징들에서 β (집중 모수)가 전이 행렬의 밀도를 조절함을 확인하자. 즉, 높은 β값을 가질 때(정확히 1 이상), 특정 상태의 전이를 조절하는 확률들은 비슷하다는 것이다. 이것은 다른 많은 상태로 전이 될 확률이 상당하다는 것을 뜻한다. 달리 말해, 감춰진 상태들의 마르코프 연쇄로 따라진 경로는 매우 임의적일 것이라는 것이다. 낮은 값의 β로는 오직 작은 수의 가능한 전이만 상당한 확률을 가질 것이라는 것이고, 감춰진 상태들로 따라진 경로는 어느 정도 추측 가능 할 것이라는 것을 뜻한다.
두 단계 베이지안 은닉 마르코프 모형
위의 두 가지 베이지안 예시들의 대안은 또 다른 단계의 전이 행렬을 위한 사전 매개변수를 더하는 것일 것이다. 즉, 다음 행을 바꾸는 것이다.
| β | = | 전이 행렬의 밀도를 조절하는 집중 초 모수 | ||||
| ~ |
위의 행을 다음으로:
| γ | = | 얼마나 많은 상태들이 본질적으로 있을 지를 조절하는 집중 초 모수 | ||||
| β | = | 전이 행렬의 밀도를 조절하는 집중 초 모수 | ||||
| η | = | 주어진 상태의 본질적 확률을 명시하는 확률들로 이루어진 N-차원 벡터. | ||||
| η | ~ | |||||
| ~ |


이것이 의미하는 것은 다음과 같다:
- η은 상태들의 어떤 상태가 본질적으로 가능할 지를 명시하는 확률 분포이다. 이 벡터의 주어진 상태의 확률이 더 클 수록, 시작 상태와 상관 없이 그 상태로 전이할 가능성이 높다.
- γ은 η의 밀도를 조절한다. 1보다 큰 값들은 모든 상태가 비슷한 사전 확률들을 가지는 밀집한 벡터를 야기할 것이다. 1보다 작은 값들은 오직 약간의 상태들만 본직적으로 가능한 밀도가 낮은 벡터를 야기한다(0 보다 큰 사전 확률들 가지고 있다).
- β는 전이 행렬의 밀도를 조절하거나, 더 정확하게는 상태 i에서 다른 상태로 전이하는 확률을 명시하는 N개의 다른 확률 벡터의 밀도를 조절한다.
β 값이 1보다 상당히 클 때를 생각해보자. 그렇다면 다른 φ 벡터들은 밀도가 높을 것이다. 확률 질량이 매우 고루 모든 상태들에 퍼져있을 것이다. 그러나 평평하지 않게 퍼질 수도 있는데, η가 어느 상태들이 다른 상태들 보다 더 질량을 가질지 조절한다.
이제, β가 1보다 낮을 때를 생각해보자. 이것은 φ 벡터들을 밀도가 낮게 만들 것이다. 거의 모든 확률 질량은 소수의 상태들에 분배되어 있고 다른 상태들에게는 거의 전이가 되지 않을 것이다. 여러 φ 벡터가 각 시작 상태에 있는 것과 그 벡터가 밀집도가 낮더라도 다른 벡터들이 질량을 다른 종결 상태들에 분배할 것임을 상기하자. 그러나 다른 모든 벡터에 대해서 η는 어느 종결 상태들이 그들에게 할당 된 질량을 더 얻을 것인지를 조절한다. 예를 들어 만약 β가 0.1이라면, 각 φ는 밀도가 낮을 것이고, 주어진 어떠한 시작 상태 “i”에 대해서도 어느 전이들이 일어날지에 대한 상태들의 집합 은 매우 작을 것이다. 일반적으로 그것은 하나나 둘 정도의 상태를 포함 할 것이다. 만약 η에 있는 확률들이 모두 같으면(또는 동치로, 위의 모델 중 하나가 η 없이 쓰였다면), 각각의 “i”에 대해서 해당하는 에 각기다른 상태들이 있을것이다. 그리고 모든 상태들은 주어진 안에서 동일하게 발생할 것이다. 반면에, η안에 있는 값들이 하나의 상태가 다른 상태들 보다 높은 확률을 갖게하도록 균형잡히지 않았다면, 거의 모든 가 이 상태를 포함할 것이다. 그러므로 시작 상태와 관련없이, 전이는 주어진 상태에 거의 항상 일어날 것이다.

그러므로, 두 단계의 모델은 독립적인 조절을 (1) 전체적인 전이 행렬의 밀도와 (2) 어느 전이가 가능할 지에 대한 상태의 밀도에 대해 가능하게 한다. 어느 특정 상황이 더 일어 날 지를 무시함을 가정해도 두 가지 경우에 이것은 실행된다. 만약 이 정보를 모델에 추가하는 것이 바람직하다면 확률 벡터 η는 직접적으로 결정 될 수 있다. 만약 이 상대적 확률들에 확신이 적다면, 비대칭 디리클레 분포가 η에 대한 사전 분포로 쓰일 수 있다. 즉, 단일 모수 γ를 가지는 대칭 디리클레 분포를 사용하는 대신에(동치로, 모든 값이 γ인 벡터를 가지는 일반 디리클레), 어떤 상태가 더 혹은 덜 선호 되는 가에 따라 γ 보다 다양하게 크거나 작은 값들을 가지는 일반적인 디리클레를 사용하는 것이다.
은닉 마르코프 모형의 응용
음성 인식에의 응용
음성을 인식하기 위해서는 먼저 주어진 음성이 어떤 문자열로부터 비롯되어있는지를 판단해야 한다. 은닉 마르코프 모형의 관점에서 음성은 "특정한 문자열로부터 도출된 출력 변수"로 여겨질 수 있고, 따라서 은닉 마르코프 모형의 최적해를 찾는 과정은 "관찰된 출력 변수(음성)를 가장 잘 설명하는 은닉 상태(문자열)"을 찾는 과정이라고 여겨질 수 있다. 이러한 모델은 비터비 알고리즘을 이용하여 최적해를 찾아낼 수 있으며 음성 인식 분야에서 널리 이용되고 있다.
생물정보학에의 응용
생물정보학의 주된 작업중 하나는 새롭게 밝혀진 유전자 서열을 다양한 방법으로 분석하는 것이다. 하지만 일반적으로 유전자 서열의 데이터는 크기가 매우 크기 때문에 이를 처리할 수 있는 정보 가공 기술이 요구되고는 한다. 은닉 마르코프 모형은 생물정보학에서 이러한 정보 처리에 사용되는 대표적인 도구이다. 은닉 마르코프 모형은 주로 유전자 예측(Gene prediction), 다중 서열 정렬 (Multiple sequence alignment), DNA 서열 에러 모델링(Modeling DNA seqeuencing error), 단백질 2차 구조 예측(Protein secondary structure prediction), ncRNA 식별(ncRNA identification), 비코딩 RNA의 위치 확인(Fast noncoding RNA annotation)등에 이용된다.

위의 그림은 주어진 유전자 서열에서 엑손과 인트론의 통계적 차이점을 밝혀내기 위한 은닉 마르코프 모형의 예시이다. 해당 은닉 마르코프 모형은 4개의 상태를 가지고 있는데, , , 는 각각 엑손에서 발견된 코돈의 첫번째, 두번째, 세번째 염기를 의미한다. 는 인트론의 염기를 의미한다. 위의 은닉 마르코프 모형은 각각 여러개의 코돈을 내포한 다수의 엑손과 다양한 길이의 인트론을 표현할 수 있다는 점에 주목하자. 위와 같은 예시는 우리가 관심있는 유전자 서열의 구조와 중요한 특성을 알고 있다면 이를 간단히 위와 같은 은닉 마르코프 모형로써 표현할 수 있다는 것을 보여준다.




금융공학에의 응용
은닉 마르코프 모형은 금융 시계열 데이터 분석에도 응용될 수 있다. 몇몇 논문들은 대부 은행을 이용하는 고객들의 특성을 모델링하여 몇가지 그룹으로 분류하는 작업에서 은닉 마르코프 모형이 K-최근접 이웃 알고리즘을 이용할 때 보다 더 나은 성과를 보여주었다고 주장한다.
기타 널리 사용되는 분야
은닉 마르코프 모형은 직접 관측할 수 없는 데이터 열과 이에 의존하는 다른 데이터들이 있을 때 데이터 열을 복원하는 것을 목표로 하는 다양한 분야에 적용 가능하다. 응용분야로는 다음과 같은 것들을 포함한다.
응용시 고려해야 할 사항들
사용할 모델의 선택

에르고딕(ergodic) 모델

좌우(left-to-right) 모델

은닉 마르코프 모형에는 상태들의 전이 구성에 따라 몇 가지 알려진 모델들이 있다. 이 때 주어진 문제에 따라 적합한 아키텍처를 선택하는 것은 중요하다. 가장 널리 쓰이는 모델로는 에르고딕(ergodic) 모델과 좌우(left-to-right) 모델이 있다. 좌우 모델은 어떤 상태로 들어가면 뒤로 돌아 갈 수 없다는 특징이 있다. 따라서 위의 구체적인 예제에서 언급한 철수와 영희 문제 모델링 하는데 좌우 모델을 선택한다면 이는 잘못된 선택이다. 이 경우 오늘의 날씨가 맑고(Sunny) 내일 비가 온다면(Rainy) 모레 이후로는 맑은 날씨가 나타날 수 없게 된다.
반면 음성 인식이나 온라인 필기 인식처럼 어떤 부분 패턴이 지나간 후에 그것이 다시 나타나지 않는 상황에서는 좌우 모델이 많이 사용된다. 이에 주로 해당하는 응용 분야는 음성 인식이나 온라인 필기 인식 등이 있다.
같이 보기
외부 링크
개념 보충 설명
- 은닉 마르코프 모형에 대한 자세한 설명 Mark Stamp 저, San Jose State University.
- EM과정에 기반한 은닉 마르코프 모형 계산
- 전환 자기회귀 은닉 마르코프 모형 (Switching Autoregressive 또는 SAR HMM)
- 은닉 마르코프 모형 튜토리얼 Archived 2017년 8월 13일 - 웨이백 머신
- 은닉 마르코프 모형 "간단한 수학을 이용한 설명 페이지"
- 은닉 마르코프 모형
- 은닉 마르코프 모형 : 기초와 응용 Part 1, Part 2 (V. Petrushin 작성)
- 제이슨 아이스너의 강의 Video 와 interactive spreadsheet
소프트웨어
- 매트랩을 위한 은닉 마르코프 모형 툴박스 (케빈 머피 제작)
- 은닉 마르코프 모형 툴킷 (HTK) 은닉 마르코프 모형의 제작 및 조작에 유용한 툴킷박스
- R을 위한 은닉 마르코프 모형 "이산 은닉 마르코프 공간에서 추론을 하기 위한 도구"
- HMMlib 은닉 마르코프 모형 기능을 제공하는 최적화된 라이브러리
- parredHMMlib 전향 알고리즘과 비터비 알고리즘에 대한 병렬적 구현으로, 상태 공간이 작을 때 매우 빠르다
- zipHMMlib 전향 알고리즘의 반복되는 작업을 크게 단순화시킨 일반적인 은닉 마르코프 모형 라이브러리
- GHMM 라이브러리 GHMM 라이브러리 프로젝트의 홈페이지
- The hmm package "은닉 마르코프 모형을 구현한 하스켈 라이브러리"
- GT2K 조지아 공대 동작 인식 툴킷
- 비터비 모델을 계산해주는 온라인 은닉 마르코프 모형 페이지
- OpenCV 기반 은닉 마르코프 모형 클래스
- MLPACK 은닉 마르코프 모형을 C++로 구현한 라이브러리